
Figura 1: Cuatro colonias de Aspergillus con morfología colonial circular.
Me pregunté, ¿cómo es que emerge un círculo a partir de estos pequeños agentes biológicos individuales? Los mecanismos de percepción de los individuos en una colonia de moho solo son sensibles a la presencia de otros individuos y de alimento en una proximidad inmediata. Las hifas y las esporas no tienen conciencia de la forma de la colonia entera como para decidir sobre su geometría. Así que, ¿cómo logran una redondez tan perfecta? La respuesta puede estar en la uniformidad de su propagación.
Video 1: Ciclo de vida del género Penicilium
En el caso del género Penicilium, por ejemplo, las esporas se dispersan alrededor de los conidióforos, de manera más ó menos aleatoria. Dentro de esta vecindad, se desarrollan nuevas hifas con codinióforos, que a su vez, dispersan esporas a su alrededor. Este proceso se repite, para formar la colonia.
El proceso me recordó al juego de la vida de Conway. Una simulación de una especie de cultivo bacteriano con autómatas celulares. Bajo ciertas condiciones iniciales, el juego de la vida de Conway puede producir patrones expansivos remotamente semejantes a un círculo.
Video 2: Secuencia de explosión con el juego de la vida de Conway.
Stephen Wolfram ha contribuido a la investigación de autómatas celulares que producen patrones circulares. En el sitio del Wolfram demostrations project, hay una animación interactiva que ilustra su trabajo en el tema. Se trata de un autómata celular que produce patrones casi circulares.
Inspirándome en el ciclo reproductivo del moho, yo escribí mi propio autómata celular probabilístico para producir patrones aproximadamente circulares.
El algoritmo comienza con una sola célula inmortal en el centro de una matriz de pixels. Esta célula dará a luz a nuevas células inmortales en cada iteración del algoritmo. Estas células, a su vez, harán lo mismo. Las nuevas células naceran en algún punto de la vecindad de Moore de las viejas células en cada iteración del algoritmo. En la figura 2 se ilustran las condiciones iniciales del cultivo virtual.





Busco que este patrón reproductivo se asemeje al patrón de propagación del moho en un plato de Petri.
Después de solo cinco iteraciones la forma geométrica de la colonia no se asemeja mucho a un círculo. Sin embargo, después de suficientes iteraciones, la colonia empieza a adquirir una forma redonda. En el video 3 se aprecia el crecimiento de una colonia de estos autómatas celulares probabilísticos.
A diferencia de las células de las figuras 2 - 5 (que preservan su color), las células del video 3 cambian de color según su edad. Con cada iteración cambian de color para indicar que han envejecido. Una célula nueva tiene un color rojizo. Conforme envejece, se traslada a lo largo del espectro cromático, hasta llegar a un violeta azulado. Después, se vuelve rojiza de nuevo, y el ciclo de envejecimiento se repite. Cada aro coloreado representa una generación de células en la colonia. Nótese la redondéz de los aros, y de la colonia completa.
El código fuente que escribí para generar la animación del video 3 está disponible para descargarse de dropbox.
El cultivo virtual parece circular. Pero, ¿qué tan redondo es en realidad? Para responder a esta pregunta se necesita alguna manera de medir la "redondez" del cultivo. Para hacer esta medición, comparé el cultivo con un disco dibujado utilizando una variante del algoritmo de Bersenham. El video 4 ilustra una comparación entre un cultivo virtual creciendo y un disco, a lo largo del crecimiento del cultivo. El código fuente que escribí para crear este video está disponible en github. Está disponible públicamente para que mi experimento sea reproducible. Los lectores de este artículo pueden reproducir ó modificar mi experimento libremente si así lo desean.
En el video, se despliegan métricas en 6 renglones, en la esquina inferior izquierda:
A La iteración actual del algoritmo. Ver figuras 2 - 5.
B Cantidad de pixels que componen al disco de Bersenham. Este valor se mantiene constante a lo largo de todas las iteraciones, ya que el disco es el punto de referencia utilizado para medir la redondez del cultivo.
C Cantidad de células del cultivo. Cada pixel representa una célula del cultivo. El cultivo inicia su vida en el centro del disco, y se propaga en forma más ó menos circular a lo largo de las iteraciones.
D Inicialmente, todas las células del cultivo se encuentran dentro del disco. Pero después de ciertas iteraciones, algunas nacerán fuera de la frontera del mismo. Este valor es útil para indicar el momento en el que esto sucede.
E Porcentaje del disco que está poblado por células del cultivo. Esta métrica, junto con C y B, es útil para evaluar la redondez del cultivo. Por ejemplo, si el cultivo fuese perfectamente circular, entonces, en la iteración donde el cultivo tenga la misma cantidad C de pixeles que tiene el disco (o sea, cuando C sea igual a B), el porcentaje E debería ser 100%. Sin embargo, el cultivo es solamente aproximadamente circular. Esto significa que, cuando el disco y el cultivo tengan la misma cantidad de pixeles, el porcentaje de coincidencia E no será del 100%, si no menor. Sin embargo, un valor de E cercano al 100% cuando C es igual a B indica una morfología muy aproximada a la circular. En el video, en la iteración 317, se observa el momento exacto en el que C iguala y supera a B. En este instante, el porcentaje del disco que se encuentra poblado por células es muy cercano al 100%. En otras palabras: en ese instante las células del cultivo están acomodadas de tal forma que logran llenar casi completamente un disco perfectamente circular, y compuesto con la misma cantidad de pixels que tiene el cultivo.
F Es simplemente una comparación entre el "tamaño" (en pixels) del cultivo, y el del disco. Cuando F es 100%, se debe a que C ha igualado a B.
El video muestra cómo un proceso aleatorio puede producir una geometría casi perfectamente redonda. Esto evoca el trabajo de A. K. Dewdney en la simulación de reacciones Belousov-Zhabotinsky. Y en términos más generales, es un ejemplo del concepto filosófico de la emergencia.
Me siento tentado a concluir que la morfología circular de las colonias de moho se debe a un proceso simple de emergencia. La proximidad de los nuevos individuos de la colonia con respecto a sus padres es lo que produce la morfología colonial circular. Si el proceso reproductivo individual se repite muchas veces, emergen los mismos tipos de figuras que se muestran en mis videos.
Me vienen a la mente pocos usos prácticos que pudiesen dársele a este trabajo. Quizás podría utilizarse para modelar patrones reales de propagación del moho. También se me ocurre que podría considerarse como un nuevo algoritmo para llenar (aproximadamente) un disco sobre una cuadrícula de pixels, con características de complejidad en el espacio y el tiempo, distintas al ya conocido algoritmo de Bersenham.
Otros estudios se han hecho con diferentes especies de hongos, como el moho mucilaginoso. Recientemente Masashi Aono desarrolló un nuevo algoritmo que supera a los algoritmos conocidos para resolver el famoso problema SAT, basándose en el comportamiento de este tipo de hongo. Concluyo mi artículo de hoy con un video de sus experimentos.
El algoritmo comienza con una sola célula inmortal en el centro de una matriz de pixels. Esta célula dará a luz a nuevas células inmortales en cada iteración del algoritmo. Estas células, a su vez, harán lo mismo. Las nuevas células naceran en algún punto de la vecindad de Moore de las viejas células en cada iteración del algoritmo. En la figura 2 se ilustran las condiciones iniciales del cultivo virtual.
Figura 2: La primer célula del cultivo. Su vecindad de Moore está indicada por los cuadros con borde verde a su alrededor.
En el algoritmo, inicialmente se selecciona aleatoriamente alguno de los pixels de la vecindad de Moore de la primer célula. En el pixel seleccionado se coloca una nueva célula. La figura 3 muestra el nuevo estado de la matriz, después de la primer iteración. Ha nacido una nueva célula en algún lugar aleatorio de la vecindad de Moore de la primer célula. Esa nueva célula es verde. La vecindad de Moore total de ambas células se indica por el borde azul. Esta es el área donde cada célula actual dará a luz a una nueva, en la próxima iteración.

Figura 3: Primer iteración de la colonia.
Cada una de las dos células da a luz a una nueva en la segunda iteración del algoritmo. El estado de la matriz después de la segunda iteración se ilustra en la figura 4,

Figura 4: Tercera iteración de la colonia.
Las figuras 5.a y 5.b ilustran la cuarta y quinta iteración, respectivamente.

Figura 5.a: Cuarta iteración.

Figura 5.b: Quinta iteración.
Busco que este patrón reproductivo se asemeje al patrón de propagación del moho en un plato de Petri.
Después de solo cinco iteraciones la forma geométrica de la colonia no se asemeja mucho a un círculo. Sin embargo, después de suficientes iteraciones, la colonia empieza a adquirir una forma redonda. En el video 3 se aprecia el crecimiento de una colonia de estos autómatas celulares probabilísticos.
Video 3: Crecimiento gradual de un cultivo virtual de autómatas celulares probabilísticos como el descrito en las figuras 2 - 5.
A diferencia de las células de las figuras 2 - 5 (que preservan su color), las células del video 3 cambian de color según su edad. Con cada iteración cambian de color para indicar que han envejecido. Una célula nueva tiene un color rojizo. Conforme envejece, se traslada a lo largo del espectro cromático, hasta llegar a un violeta azulado. Después, se vuelve rojiza de nuevo, y el ciclo de envejecimiento se repite. Cada aro coloreado representa una generación de células en la colonia. Nótese la redondéz de los aros, y de la colonia completa.
El código fuente que escribí para generar la animación del video 3 está disponible para descargarse de dropbox.
El cultivo virtual parece circular. Pero, ¿qué tan redondo es en realidad? Para responder a esta pregunta se necesita alguna manera de medir la "redondez" del cultivo. Para hacer esta medición, comparé el cultivo con un disco dibujado utilizando una variante del algoritmo de Bersenham. El video 4 ilustra una comparación entre un cultivo virtual creciendo y un disco, a lo largo del crecimiento del cultivo. El código fuente que escribí para crear este video está disponible en github. Está disponible públicamente para que mi experimento sea reproducible. Los lectores de este artículo pueden reproducir ó modificar mi experimento libremente si así lo desean.
Video 4: Crecimiento de una colonia circular de autómatas celulares.
En el video, se despliegan métricas en 6 renglones, en la esquina inferior izquierda:
- Iteración: A
- Pixels del disco: B
- Pixels del cultivo: C
- Hay D pixels del cultivo dentro del disco.
- El disco está E% lleno.
- El área del cultivo es F% el área del disco.
A La iteración actual del algoritmo. Ver figuras 2 - 5.
B Cantidad de pixels que componen al disco de Bersenham. Este valor se mantiene constante a lo largo de todas las iteraciones, ya que el disco es el punto de referencia utilizado para medir la redondez del cultivo.
C Cantidad de células del cultivo. Cada pixel representa una célula del cultivo. El cultivo inicia su vida en el centro del disco, y se propaga en forma más ó menos circular a lo largo de las iteraciones.
D Inicialmente, todas las células del cultivo se encuentran dentro del disco. Pero después de ciertas iteraciones, algunas nacerán fuera de la frontera del mismo. Este valor es útil para indicar el momento en el que esto sucede.
E Porcentaje del disco que está poblado por células del cultivo. Esta métrica, junto con C y B, es útil para evaluar la redondez del cultivo. Por ejemplo, si el cultivo fuese perfectamente circular, entonces, en la iteración donde el cultivo tenga la misma cantidad C de pixeles que tiene el disco (o sea, cuando C sea igual a B), el porcentaje E debería ser 100%. Sin embargo, el cultivo es solamente aproximadamente circular. Esto significa que, cuando el disco y el cultivo tengan la misma cantidad de pixeles, el porcentaje de coincidencia E no será del 100%, si no menor. Sin embargo, un valor de E cercano al 100% cuando C es igual a B indica una morfología muy aproximada a la circular. En el video, en la iteración 317, se observa el momento exacto en el que C iguala y supera a B. En este instante, el porcentaje del disco que se encuentra poblado por células es muy cercano al 100%. En otras palabras: en ese instante las células del cultivo están acomodadas de tal forma que logran llenar casi completamente un disco perfectamente circular, y compuesto con la misma cantidad de pixels que tiene el cultivo.
F Es simplemente una comparación entre el "tamaño" (en pixels) del cultivo, y el del disco. Cuando F es 100%, se debe a que C ha igualado a B.
El video muestra cómo un proceso aleatorio puede producir una geometría casi perfectamente redonda. Esto evoca el trabajo de A. K. Dewdney en la simulación de reacciones Belousov-Zhabotinsky. Y en términos más generales, es un ejemplo del concepto filosófico de la emergencia.
Conclusiones
Me siento tentado a concluir que la morfología circular de las colonias de moho se debe a un proceso simple de emergencia. La proximidad de los nuevos individuos de la colonia con respecto a sus padres es lo que produce la morfología colonial circular. Si el proceso reproductivo individual se repite muchas veces, emergen los mismos tipos de figuras que se muestran en mis videos.
Me vienen a la mente pocos usos prácticos que pudiesen dársele a este trabajo. Quizás podría utilizarse para modelar patrones reales de propagación del moho. También se me ocurre que podría considerarse como un nuevo algoritmo para llenar (aproximadamente) un disco sobre una cuadrícula de pixels, con características de complejidad en el espacio y el tiempo, distintas al ya conocido algoritmo de Bersenham.
Otros estudios se han hecho con diferentes especies de hongos, como el moho mucilaginoso. Recientemente Masashi Aono desarrolló un nuevo algoritmo que supera a los algoritmos conocidos para resolver el famoso problema SAT, basándose en el comportamiento de este tipo de hongo. Concluyo mi artículo de hoy con un video de sus experimentos.
.gif)
.gif)
.gif)


.gif)
.gif)
.gif)
.gif)
.gif)
.gif){kind=link}
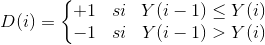{kind=link}