Durante mis experimentos construí dos tipos de redes neuronales recurrentes:
I. Redes Elman que manejan números de punto flotante en sus entradas y salidas
II. Redes Elman que manejan valores binarios en sus entradas y salidas.
En este artículo me enfocaré únicamente en el tipo II: Redes Elman con entradas y salidas binarias. Mi intención es explicar de forma comprensible mi propia implementación de una red Elman binaria.
Una explicación del problema que intenté resolver
En específico, yo quería usar los datos de fluctuaciones pasadas en el precio de una moneda, para predecir sus fluctuaciones futuras. En otras palabras, lo que yo quería hacer era usar el pasado para predecir el futuro.
Algunos analistas de mercado sostienen que hay patrones en las fluctuaciones de los precios. A estos patrones se les conoce como "tendencias de mercado". Existe la creencia de que se puede saber si un precio va a subir ó a bajar en el futuro, evaluando los patrones pasados de subidas y bajadas en dicho precio.
Existen varias herramientas de análisis técnico que se utilizan para intentar predecir tendencias en los precios. Sin embargo, también hay escepticismo acerca de su eficacia. De hecho, una de las razones por las que desistí en mis intentos de predecir las tendencias en las tasas de cambio, fue porque me vi persuadido por los argumentos de los escépticos. Pero ese es un tema para otro artículo.
Antes de enterarme sobre el escepticismo que existía acerca del análisis técnico, investigué varios métodos de análisis tecnico para predecir tendencias de mercado. Empecé probando con los indicadores MACD, y los modelos ARIMA. Pero los abandoné cuando me enteré de que el estado del arte eran las redes neuronales recurrentes. Me propuse a reproducir un experimento que leí en un artículo en el que implementaban una red neuronal Elman para predecir fluctuaciones en las tasas de cambio.
Para ejemplificar mi interpretación del experimento descrito en este artículo, utilizaré el siguiente historial de tasas de cambio entre el EUR (Euro) y el USD (dólar estadounidense):
| Índice | Fecha | Precio de 1 euro (en dólares) |
Tasa de retorno logarítmica | Media móvil de R(i) n = 5 |
Dirección del precio -1 = bajó +1 = subió |
| i | T(i) | Y(i) | R(i) | M(n, i) | D(i) |
| 0 | 2/marzo/2015 | 1.1227 | - | - | - |
| 1 | 3/marzo/2015 | 1.1168 | -0.0052690455 | - | -1 |
| 2 | 4/marzo/2015 | 1.1124 | -0.0039476096 | - | -1 |
| 3 | 5/marzo/2015 | 1.1069 | -0.004956528 | - | -1 |
| 4 | 6/marzo/2015 | 1.0963 | -0.0096224417 | - | -1 |
| 5 | 9/marzo/2015 | 1.086 | -0.0094396522 | -0.0066470554 | -1 |
| 6 | 10/marzo/2015 | 1.0738 | -0.0112974625 | -0.0078527388 | -1 |
| 7 | 11/marzo/2015 | 1.0578 | -0.0150124794 | -0.0100657127 | -1 |
| 8 | 12/marzo/2015 | 1.0613 | 0.0033032921 | -0.0084137487 | +1 |
| 9 | 13/marzo/2015 | 1.0572 | -0.003870668 | -0.007263394 | -1 |
| 10 | 16/marzo/2015 | 1.0557 | -0.0014198497 | -0.0056594335 | -1 |
| 11 | 17/marzo/2015 | 1.0635 | 0.0073613016 | -0.0019276807 | +1 |
| 12 | 18/marzo/2015 | 1.0592 | -0.0040514495 | 0.0002645253 | -1 |
| 13 | 19/marzo/2015 | 1.0677 | 0.007992896 | 0.0012024461 | +1 |
| 14 | 20/marzo/2015 | 1.0776 | 0.0092295439 | 0.0038224885 | +1 |
Tabla 1: Tasas de cambio para el EUR/USD. Datos tomados del Banco Central Europeo
En la tabla 1, se obtiene la tasa de retorno logarítmica por medio de la siguiente fórmula:
.gif)
La media móvil es simplemente el promedio de las tasas de retorno de n=5 días previos al día T(i):
.gif)
En realidad, en el experimento original, se intenta predecir la media móvil M(n, i) de las tasas de retorno R(i), en lugar de intentar predecir directamente el precio Y(i). Esta es una manera indirecta de predecir el precio. Se hace de esta manera porque la distribución de los datos M(n, i) facilita su manejo para la red neuronal.
Finalmente, la dirección del precio D(i) se indica como un +1 cuando el precio ha subido con respecto al día anterior, y con -1 cuando ha bajado, o se ha mantenido igual:
.gif)
En el experimento original del artículo, se empezaría por tomar una sub-serie de datos, a partir de la serie completa. Por ejemplo:
Para i > 0
Ecuación 1: Tasa de retorno logarítmica.
La media móvil es simplemente el promedio de las tasas de retorno de n=5 días previos al día T(i):
Para i > n - 1
.gif){kind=link}
Ecuación 2: Fórmula para la media móvil de las tasas de retorno.
En realidad, en el experimento original, se intenta predecir la media móvil M(n, i) de las tasas de retorno R(i), en lugar de intentar predecir directamente el precio Y(i). Esta es una manera indirecta de predecir el precio. Se hace de esta manera porque la distribución de los datos M(n, i) facilita su manejo para la red neuronal.
Finalmente, la dirección del precio D(i) se indica como un +1 cuando el precio ha subido con respecto al día anterior, y con -1 cuando ha bajado, o se ha mantenido igual:
Para i > 0
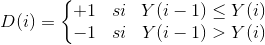{kind=link}
Ecuación 3: Fórmula para obtener la dirección binaria del precio de un instante al próximo en la serie.
En el experimento original del artículo, se empezaría por tomar una sub-serie de datos, a partir de la serie completa. Por ejemplo:
| Índice | Precio de 1 euro (en dólares) |
Media móvil n = 5 |
| j | R(j) | M(n, j) |
| 6 | -0.0094396522 | -0.0066470554 |
| 7 | -0.0112974625 | -0.0078527388 |
| 8 | -0.0150124794 | -0.0100657127 |
| 9 | 0.0033032921 | -0.0084137487 |
| 10 | -0.003870668 | -0.007263394 |
| 11 | -0.0014198497 | -0.0056594335 |
| 12 | 0.0073613016 | -0.0019276807 |
| 13 | -0.0040514495 | 0.0002645253 |
Tabla 2: Sub-serie, tomada de la tabla 1. Los números en fondo negro son el set de entrenamiento. Los números en fondo gris son el set de prueba.
Después, a la red neuronal del experimento se le darían a conocer solamente los datos R(j) y M(n, j) para 6 ≤ j ≤ 10. Con estos datos, la red se entrena para entregar un valor lo más cercano posible a M(n, j+1) cuando reciba cualquier par de valores R(j) y M(n, j) en su entrada. Se espera que, al entrenar la red con solo estos datos, esta pueda predecir correctamente los siguientes valores M(n, j+1) cuando se ingresen pares R(j) y M(n, j), pero esta vez para 10 ≤ j ≤ 12. Esto se puede interpretar como una caja negra, a la que se ingresa una serie de precios pasados para que entregue una serie de precios futuros tentativos:

Figura 1: Representación simplificada del funcionamiento de la red Elman como vaticinador de la serie temporal de precios.
A la tabla 1 se le puede agregar una columna con las predicciones de la red neuronal artificial, como se muestra en la tabla 3. En la tabla 3, los valores en fondo rosa representan las predicciones hechas por la red neuronal tipo Elman.
| Índice | Precio de 1 euro (en dólares) |
Media móvil n = 5 |
Predicciones |
| j | R(j) | M(n, j) | G(j) ≈ M(n, j+1) |
| 6 | -0.0094396522 | -0.0066470554 | -0.00760911 |
| 7 | -0.0112974625 | -0.0078527388 | -0.09521139 |
| 8 | -0.0150124794 | -0.0100657127 | -0.009000148 |
| 9 | 0.0033032921 | -0.0084137487 | -0.00712334 |
| 10 | -0.003870668 | -0.007263394 | -0.0052321533 |
| 11 | -0.0014198497 | -0.0056594335 | -0.00253321 |
| 12 | 0.0073613016 | -0.0019276807 | 0.000293525 |
| 13 | -0.0040514495 | 0.0002645253 | 0.010000121 |
Tabla 3: Se ha anexado a la tabla 2 la columna de las predicciones hechas por la red neuronal tipo Elman.
En el experimento original del artículo se utilizan varias métricas estadísticas para evaluar la calidad de las predicciones. En otras palabras, para comparar los valores en fondo rosa, con los valores en fondo gris, en la tabla 3. En este artículo no entraré en los detalles de cómo se hicieron estas evaluaciones. Tampoco entraré en los detalles de cómo se entrena, ni de cómo funciona, la red neuronal tipo I del experimento original.
Sí construí y entrené redes tipo I cuando estuve intentando reproducir el experimento del artículo. Debido a que el artículo omitía varios detalles sobre el entrenamiento de la red, implementé mi propio algoritmo genético de entrenamiento. El artículo tampoco contenía código fuente ni algoritmos en pseudocódigo, así que tuve que ponerme creativo al escribir mis programas. En este momento estoy planeando escribir otro artículo con una explicación detallada de cómo reproduje el experimento original.
En el ejemplo de la tabla 3 he usado pocos valores para simplificar la explicación del experimento del artículo. Sin embargo, en el artículo original, se utiliza una sub-serie de 1,000 datos para el set de entrenamiento, y una de 200 para el set de prueba (en lugar de los 5 y 3 datos, que he usado yo en este artículo). En mis propios intentos de reproducir el experimento, utilicé sets más pequeños: de entre 100 y 200 datos.
A pesar de que utilicé menos datos en mis propios experimentos, el tiempo de procesamiento para un solo experimento del tipo explicado aquí, resultaba ser de varios días, e incluso semanas. Debido a esto decidí disminuir la resolución de los datos, discretizándolos con la ecuación 3. De esta manera, las operaciones necesarias para entrenar la red se simplificarían, al mismo tiempo que se mantendría la esencia del experimento.
Cómo modifiqué el experimento original para acelerar el procesamiento
Entrenar la red neuronal tipo I del experimento original requiere hacer grandes cantidades de operaciones con números de punto flotante. Esto hace que el costo de cómputo sea alto.
Para reducir la complejidad de las operaciones, disminuí la resolución de los datos. De hecho, reduje la resolución al mínimo. Básicamente sacrifiqué toda la precisión de los datos, y me enfoqué únicamente en la dirección del precio. Utilicé solamente los datos D(i) de la tabla 1. Estos datos son binarios. Esto me permitió utilizar una función de transferencia muy simple en las neuronas, y por ende, simplificar enormemente el proceso de entrenamiento de la red.
Convertí la red tipo I del experimento original en una red tipo II. La arquitectura de esta red recurrente binaria se ilustra aquí:

Figura 2: Arquitectura de la red neuronal recurrente Elman con entradas y salidas binarias.
La red tipo II se puede considerar como un grafo dirigido con nodos y arcos ponderados. Los nodos son las neuronas, y los arcos las dendritas.
En el grafo, hay 4 tipos diferentes de neuronas:
- I: La neurona de entrada.
- Hx: Las neuronas ocultas.
- Cx: Las neuronas de contexto.
- O: La neurona de salida.
- Qx: Conexión desde la neurona de entrada I hacia alguna neurona oculta Hx.
- Rx,y: Conexión desde alguna neurona de contexto Cx hacia alguna neurona oculta Hy.
- Sx: Conexión desde alguna neurona Hx hacia la neurona de salida O.
- Vx: Conexión desde una neurona Hx hacia una Cx.
El algoritmo por el cual se procesan los datos en la red neuronal es una propagación ordenada de datos. En un principio, la red debe inicializarse, para posibilitar el procesamiento de datos por medio de dicho algoritmo.
La red se inicializa eligiendo un valor N, y asignando valores para todo v y todo w. El parámetro N fija la cantidad de neuronas ocultas, que debe ser igual a la cantidad de neuronas de contexto. En total hay N+1 neuronas ocultas, al igual que hay N+1 neuronas de contexto.
Una vez inicializada la red, es posible procesar datos utilizando el siguiente algoritmo de 4 etapas:
1. Etapa de entrada
En esta etapa, simplemente se carga un dato D(i) al valor acumulado de la neurona I:
.gif)
Ecuación 4: Entrada binaria de la red neuronal.
2. Etapa oculta
Los valores acumulados de la neurona de entrada y las neuronas de contexto se propagan a cada neurona oculta Hx a través de los arcos ponderados Qx y Rx,y de la siguiente manera:
Para 0 ≤ x ≤ N
.gif)
Ecuación 5: Propagación de datos hacia las neuronas ocultas.
La función de transferencia de las neuronas queda implícita en la ecuación 5. Se trata de una simple función de escalón tipo Heaviside.
3. Preparación del contexto para la próxima iteración
Dado que los datos ingresados a la red corresponden a una serie temporal, se preservan datos de contexto en las neuronas Cx para dotar de una memoria profunda a la red.
Para 0 ≤ x ≤ N
.gif)
Ecuación 6: Propagación hacia las neuronas de contexto.
.gif)
Ecuación 7: Respaldo de contexto para la red recurrente.
4. Etapa de salida
Finalmente, la salida binaria de la red se obtiene por medio de la propagación desde las neuronas ocultas hacia la neurona de salida.
.gif)
Ecuación 8: Salida binaria de la red.
Estas cuatro etapas se repiten, para valores incrementales de i, hasta llegar al final de la sub-serie. En un proceso de entrenamiento de la red, se comparan las salidas generadas G(i) con los datos D(i+1), y se perturban los pesos de los arcos en la medida en la que haya discrepancias. Es decir: la red se entrena para entregar a su salida v(O) el valor del día siguiente D(i+1), cada que recibe en su entrada un valor v(I) = D(i). Formulé dos procesos de entrenamiento: uno basado en un algoritmo avaro simple, y otro basado en recocido simulado.
Implementación de la red neuronal en ANSI C
Elegí el lenguaje de programación C porque lo conozco bien. Además de que me gusta trabajar en C porque permite apreciar claramente todo lo que está sucediendo a bajo nivel con la memoria y el procesador.
Lo primero es construir una estructura de datos que almacene los atributos de la red neuronal de la figura 2.
#define N 2 typedef struct red{ /* Red neuronal binaria Elman */ /* Valores acumulados de las neuronas */ int vI; int vH[N + 1]; int vC[N + 1]; int vO; /* Pesos de las conexiones */ int wQ[N + 1]; int wR[N + 1][N + 1]; int wS[N + 1]; int wV[N + 1]; } Red, *RedPtr;
Para inicializar la red se requieren varias funciones. Una para asignar memoria a la estructura de datos anterior y otra para liberar dicha memoria:
RedPtr asignar_mem_red(){ /* Asignar memoria a una red neuronal */ return malloc(sizeof(Red)); } void liberar_mem_red(RedPtr red){ /* Liberar memoria de la red */ free(red); }
También se necesita una función para hacer la asignación de valores necesaria para procesar los datos de la red:
int inicia_red(RedPtr red){ /* Inicializacion de los valores de la red */ int x, y; /* Valor acumulado de I */ red->vI = 1; for(x = 0; x <= N; x ++){ /* Valores acumulados de las neuronas ocultas */ red->vH[x] = 1; /* Valores acumulados de las neuronas de contexto */ red->vC[x] = 1; /* Pesos de las conexiones */ red->wQ[x] = 0; for(y = 0; y <= N; y ++){ red->wR[x][y] = 0; } red->wS[x] = 0; /* Los pesos w(Vx) se fijan a 1 para el respaldo de contexto */ red->wV[x] = 1; } /* Valor acumulado de O */ red->vO = 1; return 0; }
Una vez inicializada la red neuronal, es posible procesar datos en la misma. Los cuatro pasos del algoritmo de propagación se implementan en las siguientes cuatro funciones:
int etapa_entrada(RedPtr red, int Di){ /* 1. Etapa de entrada */ /* Ver ecuacion 4 */ red->vI = Di; return 0; } int etapa_oculta(RedPtr red){ /* 2. Etapa oculta */ /* Ver ecuacion 5 */ int x, y, sum; for(x = 0; x <= N; x ++){ sum = red->wQ[x] * red->vI; for(y = 0; y <= N; y ++){ sum += red->wR[x][y] * red->vC[y]; } if(sum <= 0){ red->vH[x] = -1; } if(sum > 0){ red->vH[x] = 1; } } return 0; } int prep_contexto(RedPtr red){ /* 3. Preparacion del contexto para la proxima iteracion */ /* Ver ecuaciones 6 y 7 */ int x; for(x = 0; x <= N; x ++){ if(red->wV[x] * red->vH[x] <= 0){ red->vC[x] = -1; } if(red->wV[x] * red->vH[x] > 0){ red->vC[x] = 1; } } return 0; } int etapa_salida(RedPtr red){ /* 4. Etapa de salida */ /* Ver ecuacion 8 */ int x, sum; sum = 0; for(x = 0; x <= N; x ++){ sum += red->wS[x] * red->vH[x]; } if(sum <= 0){ red->vO = -1; } if(sum > 0){ red->vO = 1; } return red->vO; }
Las funciones anteriores pueden utilizarse para iterar a lo largo de una sub-serie tomada a partir de los datos D(i) en la tabla 1. En la siguiente sección de código fuente, el vector D[] contiene los datos D(i) de la tabla 1.
int main(){ /* Ejemplo de una iteracion a lo largo de una sub=serie */ /* Datos D[i] tomados de la tabla 1 */ int D[] = { 0, -1, -1, -1, -1, -1, -1, -1, +1, -1, -1, +1, -1, +1, +1 }; /* Asignacion de memoria */ RedPtr red = asignar_mem_red(); /* Inicializacion de la red */ inicia_red(red); int i, error; error = 0; /* La sub-serie se toma para 3 >= i >= 11 */ for(i = 3; i <= 11; i ++){ etapa_entrada(red, D[i]); etapa_oculta(red); prep_contexto(red); etapa_salida(red); printf("D(%d) = %d, D(%d+1) = %d, G(%d) = %d\n", i, D[i], i, D[i + 1], i, red->vO); if(red->vO != D[i + 1]){ /* La prediccion G(i) discrepa con el dato D(i+1) */ error ++; printf("Discrepancia: G(%d) != D(%d+1)\n", i, i); } } /* Reportar total de discrepancias */ printf("Discrepancias: %d\n", error); liberar_mem_red(red); return 0; }
El programa anterior produce la siguiente salida textual:
D(3) = -1, D(3+1) = -1, G(3) = -1 D(4) = -1, D(4+1) = -1, G(4) = -1 D(5) = -1, D(5+1) = -1, G(5) = -1 D(6) = -1, D(6+1) = -1, G(6) = -1 D(7) = -1, D(7+1) = 1, G(7) = -1 Discrepancia: G(7) != D(7+1) D(8) = 1, D(8+1) = -1, G(8) = -1 D(9) = -1, D(9+1) = -1, G(9) = -1 D(10) = -1, D(10+1) = 1, G(10) = -1 Discrepancia: G(10) != D(10+1) D(11) = 1, D(11+1) = -1, G(11) = -1 Discrepancias: 2
Hay dos discrepancias entre la salida de la red neuronal, y la predicción correcta. Para corregir esto, es necesario entrenar la red.
Entrenamiento con un algoritmo avaro simple
El algoritmo avaro requiere varias funciones adicionales:
int borra_contexto(RedPtr red){ /* Borrar el contexto para una nueva propagacion */ int x; for(x = 0; x <= N; x ++){ /* Valores acumulados de las neuronas de contexto */ red->vC[x] = 1; } return 0; } int copia_red(RedPtr destino, RedPtr origen){ /* Copiar los atributos de la red origen a la red destino */ int x, y; /* Valor acumulado de I */ destino->vI = origen->vI; for(x = 0; x <= N; x ++){ /* Valores acumulados de las neuronas ocultas */ destino->vH[x] = origen->vH[x]; /* Valores acumulados de las neuronas de contexto */ destino->vC[x] = origen->vC[x]; /* Pesos de las conexiones */ destino->wQ[x] = origen->wQ[x]; for(y = 0; y <= N; y ++){ destino->wR[x][y] = origen->wR[x][y]; } destino->wS[x] = origen->wS[x]; /* Los pesos w(Vx) se fijan a 1 para el respaldo de contexto */ destino->wV[x] = origen->wV[x]; } /* Valor acumulado de O */ destino->vO = origen->vO; return 0; } int perturba_conexiones(RedPtr red){ /* Perturbacion de los pesos de las conexiones para modificar las predicciones G(i) */ int x, y; for(x = 0; x <= N; x ++){ /* Pesos de las conexiones */ red->wQ[x] += 1 - rand() % 3; for(y = 0; y <= N; y ++){ red->wR[x][y] = 1 - rand() % 3; } red->wS[x] = 1 - rand() % 3; // red->wV[x] = 1; } return 0; } RedPtr asignar_mem_red(){ /* Asignar memoria a una red neuronal */ return malloc(sizeof(Red)); }
Para hacer el entrenamiento más interesante, tomemos una sub-serie desde D(1) hasta D(13):
int main(){ /* Ejemplo de entrenamiento de la red con un algoritmo avaro */ /* Datos D[i] tomados de la tabla 1 */ int D[] = { 0, -1, -1, -1, -1, -1, -1, -1, +1, -1, -1, +1, -1, +1, +1 }; /* Asignacion de memoria */ RedPtr red = asignar_mem_red(); RedPtr red_de_respaldo = asignar_mem_red(); /* Inicializacion de la red */ inicia_red(red); copia_red(red_de_respaldo, red); int i, error, error_anterior; int inicio = 1; int fin = 13; /* Se asume la maxima discrepancia */ error = error_anterior = fin - inicio; int epoca; for(epoca = 0; epoca < 10000; epoca ++){ error = 0; /* La sub-serie se toma para 1 >= i >= 13 */ for(i = inicio; i <= fin; i ++){ etapa_entrada(red, D[i]); etapa_oculta(red); prep_contexto(red); etapa_salida(red); if(red->vO != D[i + 1]){ error ++; } } if(error < error_anterior){ printf("%d: Discrepancias: %d\n", epoca, error); /* Si el error se redujo con estos pesos, se hace un respaldo de la red */ error_anterior = error; copia_red(red_de_respaldo, red); } else { /* De lo contrario, se reestablece la red a su estado anterior */ copia_red(red, red_de_respaldo); } /* Se perturban aleatoriamente los pesos de la red, para producir predicciones diferentes */ perturba_conexiones(red); borra_contexto(red); } printf("Listo.\n"); liberar_mem_red(red); liberar_mem_red(red_de_respaldo); return 0; }
A este algoritmo le toma 1721 iteraciones reducir el error a 1:
0: Discrepancias: 4 11: Discrepancias: 3 368: Discrepancias: 2 1721: Discrepancias: 1 Listo.
Para conjuntos de datos D(i) grandes, es preferible utilizar una variante del recocido simulado:
int main(){ /* Ejemplo de entrenamiento de la red con una variante del recocido simulado */ /* Datos ficticios */ int D[] = { 0, -1, -1, -1, -1, -1, -1, -1, +1, -1, -1, +1, -1, +1, -1, -1, -1, -1, -1, -1, -1, +1, -1, -1, +1, -1, +1, -1, -1, -1, -1, -1, -1, -1, +1, -1, -1, +1, -1, +1, -1, -1, -1, -1, -1, -1, -1, +1, -1, -1, +1, -1, +1, +1 }; /* Asignacion de memoria */ RedPtr red = asignar_mem_red(); RedPtr red_de_respaldo = asignar_mem_red(); /* Inicializacion de la red */ inicia_red(red); copia_red(red_de_respaldo, red); int i, error, error_anterior; int inicio = 1; int fin = 40; /* Se asume la maxima discrepancia */ error = error_anterior = fin - inicio; int epoca; for(epoca = 0; epoca < 100000; epoca ++){ error = 0; /* La sub-serie se toma para 1 >= i >= 40 */ for(i = inicio; i <= fin; i ++){ etapa_entrada(red, D[i]); etapa_oculta(red); prep_contexto(red); etapa_salida(red); if(red->vO != D[i + 1]){ error ++; } } /* El modulo de la epoca establece la probabilidad de transicion */ /* Para este recocido simulado, la temperatura se mantiene constante */ /* Este algoritmo es superior al avaro para grandes cantidades de datos D(i) */ if(error < error_anterior || !(epoca % 5000)){ printf("%d: Discrepancias: %d\n", epoca, error); error_anterior = error; copia_red(red_de_respaldo, red); } else { copia_red(red, red_de_respaldo); } /* Se perturban aleatoriamente los pesos de la red, para producir predicciones diferentes */ perturba_conexiones(red); borra_contexto(red); } printf("Listo.\n"); liberar_mem_red(red); liberar_mem_red(red_de_respaldo); return 0; }
En este caso, al recocido simulado le toma solo 6378 iteraciones reducir las discrepancias a 3:
0: Discrepancias: 9
167: Discrepancias: 6
5000: Discrepancias: 17
5001: Discrepancias: 15
5002: Discrepancias: 9
5054: Discrepancias: 6
6378: Discrepancias: 3
...
95000: Discrepancias: 18
95001: Discrepancias: 9
95548: Discrepancias: 8
97518: Discrepancias: 6
Listo.
Mientras que al algoritmo avaro le toma 22337 iteraciones producir el mismo resultado:
0: Discrepancias: 9 167: Discrepancias: 6 13655: Discrepancias: 4 22337: Discrepancias: 3 Listo.
Después del entrenamiento, habría que alimentar la red con la misma sub-serie de datos D(i). Se espera que la última salida sea la predicción acertada para el día posterior al último de la sub-serie. En mis experimentos, los resultados muestran que este no siempre es el caso. De hecho, un algoritmo de predicción naive que simplemente predice en base al promedio de los datos anteriores, supera por mucho a la red neuronal recurrente binaria, dada la misma cantidad de datos para ambos métodos de predicción.
Es posible que redacte un nuevo artículo, con una justificación estadística detallada de porqué fracasó este método de predicción. En mi otro blog ya he escrito sobre un método de análisis estadístico para evaluar la calidad de las predicciones de mi red Elman binaria.
Conclusiones
A pesar de que la tecnología que intenté aplicar para resolver el problema no funcionó, aprendí mucho acerca de aprendizaje automático y redes neuronales.
He redactado este artículo para al menos sacarle algo de provecho a todo esto. Quizás resulte útil para alguien que necesite una red neuronal recurrente binaria.
El problema fueron mis suposiciones fundamentales: que era posible predecir el futuro de las fluctuaciones del mercado en base al pasado de las mismas. He redactado varias explicaciones de porqué dudo mucho que esto sea posible en otro blog.
He estado pensando en una simulación de mercado de valores con agentes económicos virtuales que utilicen este y otros métodos para tomar decisiones de inversión, de modo que un creador de mercado virtual produzca patrones de fluctuaciones en el precio de un valor virtual. Haría esto solo por curiosidad de ver los patrones que se producirían. No creo que resulte útil para modelar un mercado real.
No hay comentarios.:
Publicar un comentario